TRANSFORMER
🔍 TRANSFORMER MİMARİSİNE GENEL BAKIŞ
Transformer, 2017 yılında Google tarafından yayınlanan “Attention is All You Need” makalesi ile tanıtılan bir yapay sinir ağı mimarisidir.
🚀 RNN VE LSTM’YE GÖRE FARKLILIKLARI
Transformer modelinin en büyük yeniliği, önceki doğal dil işleme (NLP) modellerinde yaygın olarak kullanılan:
- RNN (Recurrent Neural Networks)
- LSTM (Long Short-Term Memory)
gibi zaman bağımlı yapıları tamamen ortadan kaldırmasıdır.
Bunun yerine, tamamen attention (dikkat) mekanizmalarıyla çalışır.
⚙️ PERFORMANS VE VERİMLİLİK
Transformer mimarisinin dikkat çeken avantajları şunlardır:
- Büyük veri setleri üzerinde paralel işlem yapabilme yeteneği
- RNN gibi sıralı işlemeye gerek duymadan daha hızlı sonuçlar üretmesi
- Daha verimli kaynak kullanımı
Bu sayede transformer tabanlı modeller (örneğin BERT, GPT, T5) modern NLP uygulamalarında endüstri standardı haline gelmiştir.
🌐 TRANSFORMER’IN UYGULAMA ALANLARI
Transformer, ilk etapta makine çevirisi görevlerinde kullanılmıştı.
Ancak kısa sürede:
- Doğal dil anlama
- Metin üretimi
- Özetleme
- Soru-cevap sistemleri
gibi çok sayıda NLP görevine adapte oldu.
🧠 BERT VE T5: TRANSFORMER’IN ÜZERİNDE YÜKSELEN MODELLER
2018 yılında Google, Transformer mimarisini temel alarak şu büyük modelleri tanıttı:
BERT (Bidirectional Encoder Representations from Transformers)
→ Cümle içindeki kelimeleri çift yönlü anlamaya odaklanır.T5 (Text-to-Text Transfer Transformer)
→ Her NLP görevini bir metinden metne dönüştürme mantığıyla çalışır.
Bu modeller, NLP’de devrim niteliğinde gelişmelerin öncüsü olmuştur.
title: “TRANSFORMER NEDİR? | ATTENTION IS ALL YOU NEED” date: 2025-05-02 12:00:00 +0300 categories: [Yapay Zeka, NLP] tags: [transformer, attention, huggingface, nlp, deep learning, makine öğrenmesi, google, bert, t5] —
🔍 TRANSFORMER MİMARİSİNE GENEL BAKIŞ
Transformer, 2017 yılında Google tarafından yayınlanan “Attention is All You Need” makalesi ile tanıtılan bir yapay sinir ağı mimarisidir.
🚀 RNN VE LSTM’YE GÖRE FARKLILIKLARI
Transformer modelinin en büyük yeniliği, önceki doğal dil işleme (NLP) modellerinde yaygın olarak kullanılan:
- RNN (Recurrent Neural Networks)
- LSTM (Long Short-Term Memory)
gibi zaman bağımlı yapıları tamamen ortadan kaldırmasıdır.
⚙️ PERFORMANS VE VERİMLİLİK
Transformer mimarisinin dikkat çeken avantajları şunlardır:
- Büyük veri setleri üzerinde paralel işlem yapabilme yeteneği
- RNN gibi sıralı işlemeye gerek duymadan daha hızlı sonuçlar üretmesi
- Daha verimli kaynak kullanımı
Bu sayede transformer tabanlı modeller (örneğin BERT, GPT, T5) modern NLP uygulamalarında endüstri standardı haline gelmiştir.
🌐 TRANSFORMER’IN UYGULAMA ALANLARI
Transformer, ilk etapta makine çevirisi görevlerinde kullanılmıştı.
Ancak kısa sürede:
- Doğal dil anlama
- Metin üretimi
- Özetleme
- Soru-cevap sistemleri
gibi çok sayıda NLP görevine adapte oldu.
🧠 BERT VE T5: TRANSFORMER’IN ÜZERİNDE YÜKSELEN MODELLER
2018 yılında Google, Transformer mimarisini temel alarak şu büyük modelleri tanıttı:
BERT (Bidirectional Encoder Representations from Transformers)
→ Cümle içindeki kelimeleri çift yönlü anlamaya odaklanır.T5 (Text-to-Text Transfer Transformer)
→ Her NLP görevini bir metinden metne dönüştürme mantığıyla çalışır.
🆚 TRANSFORMER VE GELENEKSEL MODELLERİN KARŞILAŞTIRMASI
İşlem Yapma Şekli, Bağımlılık, Eğitim ve Verimlilik
| Özellik | Transformer | RNN | LSTM |
|---|---|---|---|
| İşlem Yapma Şekli | Paralel işlem (tüm kelimeler aynı anda işlenir) | Sırasıyla işlem (önceki adımın çıktısı bir sonraki adıma aktarılır) | Sırasıyla işlem, ancak daha uzun süreli bağımlılıkları öğrenebilir |
| Bağımlılıkları Öğrenme | Uzun mesafeli bağımlılıkları hızlı ve etkili öğrenir | Kısa mesafeli bağımlılıkları öğrenir, uzun mesafelerde zorlanır | Uzun mesafeli bağımlılıkları öğrenebilir (sınırlı) |
| Eğitim Süresi | Kısa sürede eğitim (paralel işlem sayesinde) | Daha uzun (sıralı işlem nedeniyle) | Uzun (sıralı işlem nedeniyle) |
| Verimlilik | Yüksek verimlilik, hızlı | Düşük verimlilik | Düşük verimlilik |
Bellek Kullanımı, Uzun Bağlantılar, Donanım
| Özellik | Transformer | RNN | LSTM |
|---|---|---|---|
| Bellek Kullanımı | Düşük, tüm ilişkileri aynı anda öğrenir | Yüksek, her kelime bir öncekine bağlı | Daha yüksek, her kelime bir öncekine bağlı |
| Uzun Bağlılıkları Öğrenme | Mükemmel, tüm kelimeler arası ilişki öğrenilir | Kısa süreli bağımlılıklar kolay, uzunlarda zorlanır | LSTM RNN’den iyi olsa da uzun süreli öğrenme sınırlı |
| Donanım İhtiyacı | GPU/TPU ile daha verimli | Daha az donanımla çalışabilir ama yavaş | Paralel işlemde verimsizdir, bazı iyileştirmelerle çalışabilir |
Uygulama, Dikkat Mekanizması ve Ölçeklenebilirlik
| Özellik | Transformer | RNN | LSTM |
|---|---|---|---|
| Uygulama Alanı | Çeviri, özetleme, metin oluşturma, soru-cevap gibi çok sayıda NLP görevi | Sınırlı görevler, genelde kısa dizilerde | Uzun dizilerde performansı iyi olabilir |
| Dikkat Mekanizması | Self-attention ile her kelime birbirine bağlanır | Dikkat mekanizması yoktur | Unutma-hatırlama mekanizmaları vardır |
| Ölçeklenebilirlik | Kolay ölçeklenebilir, büyük veri ve modellerle verimli | Sınırlı ölçeklenebilirlik | Büyük veri setlerinde yavaşlayabilir |
Transformer Mimarisi ve Bileşenleri
- Encoder-Decoder Yapısı
- Self-Attention Mekanizması
- Multi – Head Attention
- Feed-Forward Neural Network (FFN)
- Layer Normalization ve Residual Connections
- Pozisyonel Kodlama (Positional Encoding)
1- Encoder – Decoder Yapısı
• Encoder: Giriş verilerini (örneğin, bir cümlenin kelimeleri) alır ve bu veriyi daha
soyut, anlamlı temsillere dönüştürür. Encoder, giriş dizisini çeşitli katmanlarda işler
ve her katmanda daha fazla bilgi çıkarımı yaparak dilin anlamını temsil eder.
• Decoder: Encoder tarafından işlenen temsilleri kullanarak, çıkış dizisini üretir.
Decoder, çıkışı oluştururken Encoder’dan aldığı temsili ve önceki adımda ürettiği
kelimeleri dikkate alarak bir sonraki kelimeyi tahmin eder.
Encoder ve Decoder Yapısının Katmanları:
Her iki yapı da birden fazla self-attention katmanı ve feed-forward neural network (FFN) katmanı içerir.
Bu katmanlar sırasıyla giriş verilerini işler ve daha anlamlı temsiller üretir.
2- Self Attention Mekanizması
Transformer’ın en önemli özelliği, self-attention kullanarak bir cümlenin her
kelimesinin diğer tüm kelimelerle olan ilişkisini öğrenmesidir. Bu sayede
model, bir metnin her parçasının bağlamını daha iyi anlar.
Örneğin, “Kedi fareyi kovaladı” cümlesinde, “kovaladı” kelimesinin anlamı,
“kedi” ve “fare” kelimeleriyle olan ilişkisinden anlaşılır.
Self-attention, bu ilişkiyi ağırlıklandırılmış bir şekilde hesaplar ve her kelimenin bağlamsal temsilini
oluşturur. Bu sayede, uzaktaki kelimeler arasındaki ilişkiler de yakalanabilir,
ki bu RNN’lerde bir dezavantajdı.
3- Multi – Head Attention
Transformer modelindeki self-attention mekanizmasının bir uzantısıdır. Bu
teknik, birden fazla dikkat başlığını paralel olarak kullanarak, modelin farklı
bağımlılıkları aynı anda öğrenmesini sağlar.
Transformer, aynı veri üzerinde birden fazla “attention” başlığı kullanır.
Her bir başlık, farklı bir “dikkat” türünü öğrenir ve bu başlıklar daha sonra birleştirilir.
Bu, modelin veriden daha fazla bilgi edinmesini ve daha güçlü özellikler çıkarmasını sağlar.
Örneğin, bir başlık kelimeler arasındaki gramer ilişkilerini öğrenirken, başka bir başlık
anlam bağlamını öğrenebilir.
4- Feed-Forward Neural Networks (FFN)
(FFN), her self-attention katmanının ardından gelen bir yapıdır ve modelin
doğrusal olmayan işlemler yapmasına olanak tanır.
Her kelime, önceki adımlardan elde edilen dikkatli temsiller üzerinden bir feed-forward neural
network’e (tam bağlantılı bir ağ) geçirilir.
Bu ağ, genellikle iki katmandan oluşur ve aktifleştirici fonksiyonlar kullanarak daha derin temsil
öğrenmelerini sağlar.
İlk katman genellikle daha yüksek boyutlu bir dönüşüm yapar ve ikinci
katman boyutları orijinal boyuta geri döndürür.
5- Layer Normalization (Katman Normalizasyonu)
• Modelin öğrenme sürecini hızlandırır ve gradyan
patlaması/kaybolması sorunlarını azaltır.
• Her katmandan sonra uygulanarak verinin daha iyi
ölçeklenmesini sağlar.
5- Residual Connections (Artık Bağlantılar)
• Derin modellerde gradyan kaybolmasını önlemek için giriş
bilgilerini doğrudan ileri katmanlara taşır.
• Çıkış şu şekilde hesaplanır:
Çıkış = Giriş + Katman Çıktısı
Bu mekanizma, modelin daha derin katmanlar eklemesine olanak tanır ve
öğrenmeyi hızlandırır.
6- Pozisyonel Kodlama (Positional Encoding)
Transformer modeli, sırayla işlem yapmadığı için kelimelerin sırasını
anlamak adına pozisyonel kodlama kullanır.
Bu, modelin kelimelerin konumunu tanıyabilmesini ve kelimeler arasındaki sıralı bağımlılıkları
anlayabilmesini sağlar.
Pozisyonel kodlama, her kelimeye, modelin sırasını anlamasına yardımcı
olacak bir vektör ekler.
Bu vektör, genellikle sinüs ve kosinüs fonksiyonları
kullanılarak hesaplanır ve her kelimenin pozisyonuna göre farklı bir değer
alır.
Transformer Nasıl Çalışır?
Geleneksel modeller, girdileri sırayla işlerken, Transformers aynı anda
birden fazla girdiyi işleyebilir ve bu da onları çok daha hızlı ve verimli hale
getirir.
Bu başarının anahtarı ise self-attention (kendi üzerine dikkat) mekanizmasıdır.
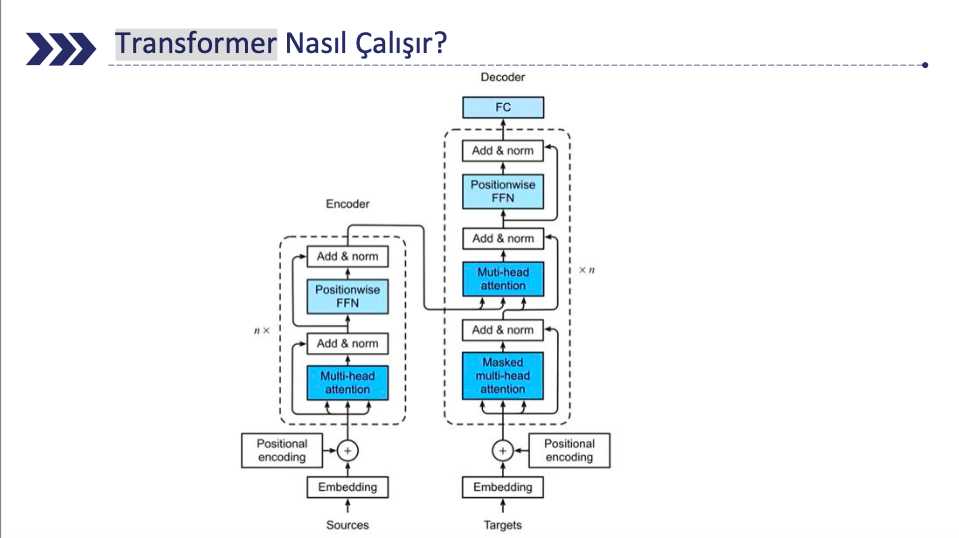
Şekil 1: Transformer Encoder ve Decoder Yapısı
Transformer Nasıl Çalışır: Encoder (Kodlayıcı) Aşamaları:
Embedding: Giriş metni, matematiksel bir vektör temsiline dönüştürülür.
Positional Encoding (Konumsal Kodlama): Gömme işlemi tamamlandıktan sonra, kelimelerin sırasını anlaması için kelimenin konumunu belirten vektörler ekleyerek sırayı korur. Bu vektörler sinüs ve kosinüs fonksiyonları ile üretilir. Böylece, benzer pozisyondaki kelimeler benzer vektör temsillerine sahip olur.

Transformer Nasıl Çalışır: Encoder (Kodlayıcı) Aşamaları:
- Multi-Head Attention (Çok Başlı Dikkat): Model, metindeki kelimeler arasındaki ilişkileri anlamak için dikkat mekanizmasını uygular.
Add & Norm (Ekle ve Normalleştir): Dikkat mekanizmasının çıktısı eklenir ve normalleştirilir.
Feed-Forward Neural Network (FFN): İleri beslemeli bir sinir ağı, veriler üzerinde daha fazla işlem yapar.
- Multi-Head Attention (Çok Başlı Dikkat): Model, metindeki kelimeler arasındaki ilişkileri anlamak için dikkat mekanizmasını uygular.
- Add & Norm: Çıktı tekrar normalleştirilir ve bir sonraki aşamaya aktarılır.
Transformer Nasıl Çalışır: Decoder (Çözücü) Aşamaları:
- Embedding: Çıkışta üretilecek metin, benzer şekilde bir vektör temsiline dönüştürülür.
- Positional Encoding: Hedef metin için sıralama bilgileri eklenir.
- Masked Multi-Head Attention (Maskeli Çok Başlı Dikkat): Çözücü, metnin daha önce üretilmiş bölümlerine odaklanır.
- Add & Norm: Dikkat çıktısı normalleştirilir.
Transformer Nasıl Çalışır: Decoder (Çözücü) Aşamaları (Devam):
- Multi-Head Attention: Kodlayıcıdan gelen verilere odaklanır ve bağlam bilgisi eklenir.
- Add & Norm: Tekrar ekleme ve normalleştirme uygulanır.
- Feed-Forward Neural Network (FFN): Çözücüde ileri beslemeli bir ağ kullanılır.
- Add & Norm: Sonuçlar normalleştirilerek bir sonraki adıma geçilir.
- Tam Bağlantılı Katman (FC): Nihai çıktıyı, yani modelin ürettiği sonucu üretir.
Önemli Transformer Modelleri: BERT (Bidirectional Encoder Representations from Transformers)
• Çift yönlü (Bidirectional) öğrenme: BERT, bir kelimenin anlamını belirlerken hem solundaki hem de sağındaki kelimeleri dikkate alır.
• Maskeli Dil Modeli (Masked Language Model - MLM): Cümlede bazı kelimeler rastgele maskelenir ve modelden bu kelimeleri tahmin etmesi istenir.
• BERT, tüm girdi dizisini aynı anda ele alarak, iki yönlü bir bağlam anlayışı sağlar.
• Daha çok anlama ve analiz için kullanılır. (Örneğin, bir metindeki duygu analizini yapmak)
Önemli Transformer Modelleri: BERT (Bidirectional Encoder Representations from Transformers) - Uygulama Alanları
• Google arama motoru sonuçlarını iyileştirme
• Anlam bazlı metin eşleştirme (Semantic Search)
• Metin özetleme
• Metin Anlamlandırma
• Kelime anlam ayrımı (Word Sense Disambiguation)
• Makine çevirisi
• Metin sınıflandırma
Önemli Transformer Modelleri: GPT (Generative Pre-trained Transformer)
• Tek yönlü (Unidirectional) öğrenme: Sadece soldan sağa doğru öğrenir ve metin tahmini yapar.
• Önceden eğitilmiş (Pre-trained) ve ardından belirli görevler için ince ayar yapılabilen bir modeldir.
• GPT, girdi dizisini sıralı olarak işleyerek, gelecekteki kelimeleri tahmin etmeye odaklanır.
Önemli Transformer Modelleri: GPT (Generative Pre-trained Transformer) - Uygulama Alanları
• Otomatik metin tamamlama
• Yapay zeka destekli sohbet botları
• Yaratıcı yazı üretme (örneğin, hikâye veya şiir yazma)
• Dil çevirisi
• Özetleme
• Bilgi getirme ve arama motorları
Önemli Transformer Modelleri: T5
• “Her şeyi metinden metne çevirme” (Text-to-Text) prensibiyle çalışır.
• Veriyi belirli bir formatta işler, örneğin:
"translate English to German: Hello, how are you?" → "Hallo, wie geht es dir?"
"summarize: Artificial intelligence is..." → "AI is..."
• Daha çok metin üretimi ve dönüştürme için kullanılır. (Örneğin, bir metni özetlemek veya bir dili başka bir dile çevirmek)
Önemli Transformer Modelleri: T5 (Text-to-Text Transfer Transformer) - Uygulama Alanları
• Metin çevirisi
• Metin özetleme
• Metin tamamlama
• Metin sınıflandırma ve duygu analizi
• Açık uçlu soru yanıtlama
• Chatbot ve diyalog sistemleri
📌 Önemli Transformer Modelleri
| Model | Özellikleri | Uygulama Alanları |
|---|---|---|
| BERT | Çift yönlü öğrenme, bağlamı tam anlama | Metin sınıflandırma, duygu analizi, arama motorları |
| GPT | Tek yönlü metin üretimi, yaratıcı yazma | Sohbet botları, hikâye ve içerik üretimi |
| T5 | Metinden metine dönüştürme | Çeviri, özetleme, soru yanıtlama |
🧪 Transformer’ın Eğitim Süreci
1. Veri Ön İşleme ve Girdi Temsili
- Metin verileri tokenize edilir (örneğin, BPE veya WordPiece tokenizasyonu).
- Tokenler gömme (embedding) vektörlerine dönüştürülür.
- Pozisyonel kodlama (positional encoding) eklenerek sırasal bilgiler korunur.
🔍 Notlar:
- BPE: Sık kullanılan kelime parçalarını tespit ederek daha küçük bir kelime dağarcığı (vocabulary) oluşturur.
- WordPiece: BPE’den farkı, sadece sık görülen çiftleri değil, istatistiksel olasılıklara dayalı birleşimleri seçmesidir. Model, maksimum olasılığa sahip olan alt kelimeleri belirler.
🔤 Tokenizasyon Örneği: BPE vs WordPiece
| Kelime | BPE Tokenizasyonu | WordPiece Tokenizasyonu |
|---|---|---|
| “unhappiness” | un + happi + ness | un ##happiness |
| “playing” | play + ing | play ##ing |
| “retraining” | re + train + ing | re ##training |
| “unbelievable” | un + believ + able | un ##believable |
🔧 Transformer’ın Eğitim Süreci
2. İleri Yayılım (Forward Pass)
- Encoder katmanları, Self-Attention ve Feed-Forward Neural Networks (FFN) kullanarak girdiyi işler.
- Decoder katmanları, hem Self-Attention hem de Cross-Attention işlemleriyle çıktı üretir.
3. Kayıp Fonksiyonunun Hesaplanması
- Çapraz entropi kaybı (Cross-Entropy Loss) genellikle kullanılır.
- Büyük dil modellerinde label smoothing gibi teknikler uygulanabilir.
4. Geriye Yayılım (Backpropagation) ve Ağırlık Güncelleme
- Optimizasyon algoritmaları (Adam, Adagrad vb.) ile modelin ağırlıkları güncellenir.
5. Öğrenme Oranının Ayarlanması (Learning Rate Scheduling)
- Transformer modelleri, sabit bir öğrenme oranı yerine özel öğrenme oranı planlayıcıları (learning rate schedulers) kullanır.
- Örneğin, warm-up döneminde öğrenme oranı kademeli olarak artırılır, ardından zamanla azaltılır.
💼 Transformer Modellerinin Kullanım Alanları
1. Makine Çevirisi
Transformer modelleri, cümleleri bir dilde başka bir dile çevirmede mükemmel sonuçlar verir. Google Translate gibi çeviri araçları, Transformer mimarisini kullanarak daha hızlı ve doğru çeviriler sağlar.
2. Metin Özetleme
Transformer modelleri, uzun metinlerin özetini çıkarmak için de kullanılabilir. Model, metnin önemli bölümlerini belirleyerek daha kısa ve anlamlı özetler üretir.
3. Soru-Cevap Sistemleri
Transformers, bir metindeki sorulara uygun cevaplar bulmada oldukça başarılıdır. Bu, müşteri hizmetleri chatbot’ları ve akıllı asistanlar gibi uygulamalarda yaygın olarak kullanılmaktadır.
4. Metin Üretimi
Transformer mimarisi, GPT-3 ve GPT-4 gibi modellerin temelini oluşturur. Bu modeller, oldukça doğal ve akıcı metinler üretebilir, hatta yaratıcı yazılar bile yazabilir. Prompt engineering teknikleri ile Transformer modelleri belirli girdilere uygun çıktılar üretmek için optimize edilebilir.
5. Sentiment Analizi ve Duygu Tanıma
Transformer modelleri, bir metnin duygusal tonunu belirleyebilir ve bu bilgiye dayanarak duygu analizi yapabilir. Bu, özellikle sosyal medya analizleri ve müşteri geri bildirimleri gibi alanlarda kullanılır.
6. Görsel-İşitsel Verilerde Kullanım
Son zamanlarda Transformers, yalnızca metinle sınırlı kalmayarak görsel ve işitsel veriler üzerinde de kullanılmaya başlanmıştır. Görüntü tanıma ve sesli komut algılama gibi görevlerde de başarılı sonuçlar vermektedir.
🎯 Attention Mekanizması
Attention mechanizması, yapay zeka ve derin öğrenme dünyasında dil işleme, görüntü tanıma ve hatta ses analizi gibi alanlarda devrim yaratan bir tekniktir. Özellikle doğal dil işleme (NLP) modellerinde, metinler arasındaki ilişkileri anlamak ve doğru tahminler yapmak için kritik bir rol oynar.
Attention mechanizması, yapay sinir ağlarının belirli girdilere daha fazla dikkat vermesini sağlayan bir tekniktir. Geleneksel derin öğrenme modelleri, her girdiyi eşit önemde değerlendirirken, attention mechanism, bir girdinin diğer girdilerle olan bağlamını öğrenir ve bu bağlamın ne kadar önemli olduğunu belirler. Bu yöntem, özellikle uzun sekans verilerinde (metinler gibi) modelin belirli kelimelere veya veri parçalarına daha fazla odaklanmasını sağlar.
Attention mekanizması, bir modelin girdi verisinin belirli bölümlerine “daha fazla dikkat etmesi” gerektiğini belirlemesine olanak tanır. Bu kavram, insanların yeni bilgileri işlerken, mevcut bilgileri ve bağlamları göz önünde bulundurarak odaklanma yeteneğinden esinlenmiştir. NLP’de, bir cümle veya metin parçası işlenirken, bazı kelimelerin veya ifadelerin anlamı üzerinde daha fazla durulması gerekebilir. Attention mekanizması, bu önemli bölümlere daha fazla “dikkat etmek” ve modelin performansını artırmak için kullanılır.
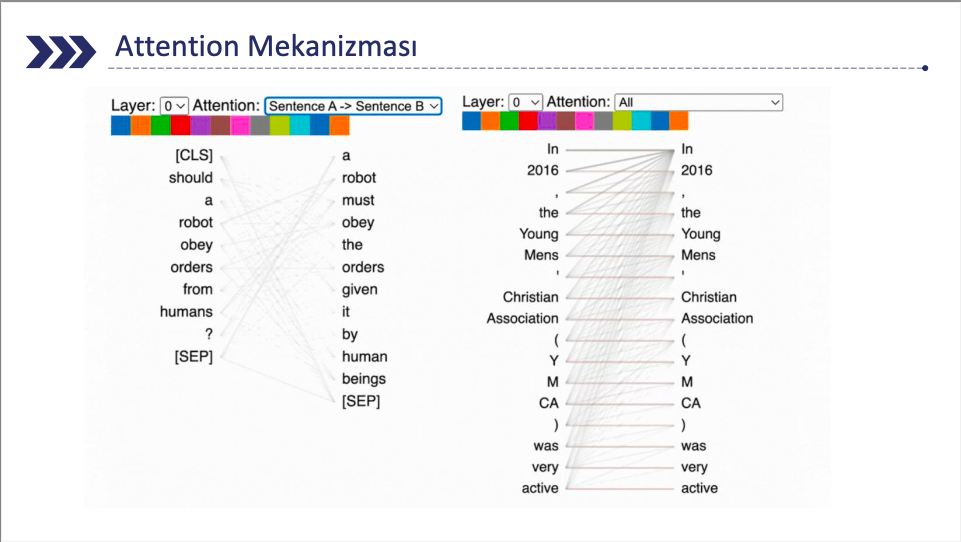
🧩 Attention Mekanizmasının Çeşitleri
Self-Attention: Bir cümlenin veya metnin içindeki her bir elemanın, diğer tüm elemanlarla olan ilişkisini değerlendirir.
Multi-Head Attention: Modelin farklı “başlıklar” (heads) üzerinden veriyi paralel olarak işlemesine olanak tanır. Her bir “head”, verinin farklı temsillerine odaklanır, böylece model aynı anda birden fazla bağlamı ve ilişkiyi değerlendirebilir. Bu, modelin genel anlama yeteneğini artırır.
Cross-Attention: Genellikle encoder-decoder yapılarında kullanılır ve decoder’ın, encoder tarafından üretilen temsillere dikkat etmesini sağlar. Bu, özellikle metin çevirisi gibi görevlerde, kaynak metnin belirli bölümlerine göre hedef metin üretirken faydalıdır.
🔬 Attention Mekanizması Nasıl Çalışır?
1. Girdi Temsili (Input Representation)
Girdiler, model tarafından belirli bir boyutta temsil edilir. Bu temsil genellikle vektörlerle yapılır ve her bir kelime veya veri parçası bir vektör olarak ifade edilir.
2. Sorgu, Anahtar ve Değer Vektörleri (Query, Key, Value Vectors)
Her bir girdiye sorgu (query), anahtar (key) ve değer (value) vektörleri atanır. Bu vektörler, girdinin diğer girdilerle olan ilişkisini öğrenmek için kullanılır. Query vektörü, diğer girdilerle olan ilişkileri sorgularken, key vektörü girdinin önemli özelliklerini taşır, value vektörü ise modelin girdiden öğrenmesi gereken bilgiye sahiptir.
3. Skor Hesaplama (Score Calculation)
Query vektörü, diğer tüm key vektörleriyle karşılaştırılarak bir skor hesaplanır. Bu skor, bir girdinin diğer girdilere ne kadar “dikkat” etmesi gerektiğini belirler. Daha yüksek skorlar, modelin bu girdilere daha fazla odaklanmasını sağlar.
4. Softmax ve Ağırlıklı Ortalama (Softmax and Weighted Average)
Skorlar softmax fonksiyonu ile normalize edilir ve her bir girdiye verilen dikkat ağırlığı belirlenir. Bu ağırlıklar, girdilerin önemini belirler ve modelin çıktıları bu ağırlıklarla hesaplanır.
5. Sonuç Üretimi (Output Generation)
Girdilere uygulanan dikkat mekanizmasının sonucunda, model en anlamlı veriyi çıkarmak için bir sonuç üretir. Bu sonuç, modelin belirli veri parçalarına ne kadar dikkat ettiğine göre şekillenir.
🔄 Attention Türleri – Soft vs Hard
| Özellik | Soft Attention | Hard Attention |
|---|---|---|
| Tanım | Tüm giriş dizisi üzerinde sürekli ve farklı ağırlıklarla çalışır. | Yalnızca belirli kelimelere odaklanır, diğerlerini göz ardı eder. |
| Çalışma Yapısı | Tüm kelimelere dikkat verilir ancak ağırlıklar değişkendir. | Seçilen kelimelerle sınırlıdır (örneğin, belirli kelimeleri “örnekleme” yoluyla seçer). |
| Avantajı | Daha stabil ve diferansiyellenebilir, bu yüzden geri yayılım (backpropagation) ile eğitilebilir. | Daha az hesaplama gerektirir, ancak öğrenmesi zor olabilir. |
| Kullanım Alanları | Çeviri, dil modelleme, metin üretimi. | Görüntü işleme, veri sıkıştırma, nesne algılama. |
🌍 Attention Türleri – Global vs Local
| Özellik | Global Attention | Local Attention |
|---|---|---|
| Tanım | Tüm giriş dizisi boyunca dikkat uygular. | Yalnızca belirli bir alt bölgeye odaklanır. |
| Çalışma Yapısı | Encoder’in tüm gizli durumlarını dikkate alarak karar verir. | Sadece belirlenen bir pencere içindeki kelimelere odaklanır. |
| Avantajı | Daha fazla bağlamsal bilgiye sahiptir. | Daha hızlıdır ve bellek kullanımı daha düşüktür. |
| Kullanım Alanları | Uzun metinler, detaylı bağlamsal ilişkiler. | Daha kısa metinler. |
🧭 Attention Visualization (Görselleştirme) Teknikleri
a) Heatmap (Isı Haritası) Kullanımı
Kelimeler arasındaki dikkat dağılımını gösterir.
- Örnek: Çeviri sırasında modelin hangi kelimeye ne kadar dikkat verdiğini görmek için kullanılır.
Örneğin, İngilizce “The cat sat on the mat.” cümlesini Türkçeye çevirirken, “cat” kelimesine en fazla dikkat verilmesi beklenir.
Heatmap, her kelimenin diğerlerine olan ilgisini gösterir.
b) Head-wise Attention Visualization
Transformer modelinde her Attention başlığının farklı görevler üstlendiğini anlamaya yarar.
- Örnek: Bazı başlıklar gramer yapısına, bazıları özne-nesne ilişkilerine odaklanabilir.
c) Attention Rollout
Farklı katmanlardaki Attention değerlerini toplayarak kelime bazlı etkisini gösterir.
Modelin uzun vadeli ilişkileri nasıl kurduğunu analiz etmek için kullanılır.
🛠️ Örnek: Transformer Modeli Oluşturma
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import torch
import torch.nn as nn
class SimpleTransformer(nn.Module):
def __init__(self, input_dim, model_dim, num_heads, num_layers):
super(SimpleTransformer, self).__init__()
self.embedding = nn.Embedding(input_dim, model_dim)
self.transformer = nn.Transformer(
d_model=model_dim,
nhead=num_heads,
num_encoder_layers=num_layers,
num_decoder_layers=num_layers
)
self.fc_out = nn.Linear(model_dim, input_dim)
🧱 Embedding ve Katman Açıklamaları
- Embedding katmanı, kelime dağarcığı boyutu ve vektör boyutunu belirler, her kelimeyi sabit bir vektörle temsil eder.
- Transformer modelinde
d_model, kelimenin boyutunu;Nhead, multi-head attention’daki başlık sayısını;num_encoder_layersvenum_decoder_layersise encoder ve decoder katman sayısını belirler. - Son olarak, Linear katman, gömme boyutunu kelime dağarcığına dönüştürerek modelin çıktısını oluşturur.
🧪 Örnek: Transformer Modeli Oluşturma (Forward Metodu)
- Forward metodu, modelin nasıl çalıştığını ve verilerin nasıl geçtiğini belirler.
- Burada,
src(source) vetgt(target) sırasıyla giriş ve hedef dizileridir.srcvetgtembedding katmanıyla vektöre dönüştürülür. Her kelime, gömme vektörleriyle temsil edilir. - Bu vektörler, Transformer modelinin encoder-decoder katmanlarına gönderilir ve dikkat mekanizmalarıyla işlenir.
- Son olarak, transformer çıktısı
fc_outkatmanına gönderilir ve burada, gömme vektörleri kelime dağarcığı boyutuna dönüştürülerek her çıkış vektörü bir kelimeyi temsil eder.
1
2
3
4
5
6
7
def forward(self, src, tgt):
src = self.embedding(src)
tgt = self.embedding(tgt)
output = self.transformer(src, tgt)
output = self.fc_out(output)
return output
🔹 Kod : Transformer Modeli Oluşturma ve Örnek Veri
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
```python
# Parametreler
input_dim = 5000 # Kelime dağarcığı boyutu
model_dim = 512 # Model boyutu
num_heads = 8 # Attention başlık sayısı
num_layers = 6 # Encoder ve decoder katman sayısı
# Model oluşturuluyor
model = SimpleTransformer(input_dim, model_dim, num_heads, num_layers)
# Örnek veri
src = torch.randint(0, input_dim, (10, 32)) # (src_length, batch_size)
tgt = torch.randint(0, input_dim, (20, 32)) # (tgt_length, batch_size)
output = model(src, tgt)
print(output.shape) # Çıktı boyutu

📏 Transformer Çıktı Boyutu Açıklaması
- 20: Her hedef cümlesi için (yani her hedef kelimesi için) modelin tahmin ettiği çıktının uzunluğu
- 32: Modelin üzerinde çalıştığı örnek sayısı gösterir.
- 5000: Her bir kelimeyi modelin 5000 boyutlu bir temsil (veya olasılık) ile tahmin ettiğini belirtir.
Bu, modelin her hedef kelimesi için (20 kelime) her bir örnekte (32 örnek) 5000 kelime
dağarcığından hangi kelimenin gelmesi gerektiğiyle ilgili bir dağılım (veya tahmin) ürettiği anlamına gelir.
Çıktı genellikle softmax fonksiyonu ile işlem görüp her kelimenin olasılıklarını temsil eder.
Bu model, dil çevirisi, metin sınıflandırması veya benzeri doğal dil işleme (NLP) görevlerine uygulanabilir.
🧪 Örnek: BERT ile Metin Anlamlandırma
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from transformers import BertTokenizer, BertModel
import torch
# BERT modelini ve tokenizer'ı yükleme
model_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
# Örnek metin
text = "BERT is a powerful language model!"
# Metni tokenleştirme ve tensöre çevirme
inputs = tokenizer(text, return_tensors="pt")
# Modeli çalıştırma
with torch.no_grad():
outputs = model(**inputs)
# Son gizli katman çıktısı
last_hidden_states = outputs.last_hidden_state
print(last_hidden_states.shape) # (1, token_sayısı, gizli_boyut)
🧪 Örnek: BERT ile Metin Anlamlandırma
```python from transformers import BertTokenizer, BertModel import torch
BERT modelini ve tokenizer’ı yükleme
model_name = “bert-base-uncased” tokenizer = BertTokenizer.from_pretrained(model_name) model = BertModel.from_pretrained(model_name)
Örnek metin
text = “BERT is a powerful language model!”
Metni tokenleştirme ve tensöre çevirme
inputs = tokenizer(text, return_tensors=”pt”)
Modeli çalıştırma
with torch.no_grad(): outputs = model(**inputs)
Son gizli katman çıktısı
last_hidden_states = outputs.last_hidden_state print(last_hidden_states.shape) # (1, token_sayısı, gizli_boyut)
```markdown
📌 Açıklamalar
BERT modelini çalıştırmak için
torch.no_grad()ile otomatik türev alma işlemini kapatıyoruz.
(Bu, modelin eğitilmesini değil, sadece tahmin yapmasını sağlar ve bellek kullanımını azaltır.)Model çalıştırıldığında giriş verisi (tokenler) modele beslenir ve çıktı alınır.
Modelin son katman çıktısını alıyoruz (
last_hidden_state) ve ekrana yazıyoruz.

🧾 Çıktı Açıklaması
Çıktının şekli (shape): (1, token_sayısı, 768)
- 1 → Cümle sayısı (tek bir cümle işliyoruz).
- token_sayısı → Cümledeki toplam kelime parçacıkları (subword tokens).
- 768 → BERT’in her token için ürettiği 768 boyutlu vektör.
🎯 Örnek: BERT ile Duygu Analizi
```python from transformers import BertTokenizer, BertForSequenceClassification import torch
BERT modelini ve tokenizer’ı yükleme (Duygu analizi için ince ayarlı model)
model_name = “nlptown/bert-base-multilingual-uncased-sentiment” tokenizer = BertTokenizer.from_pretrained(model_name) model = BertForSequenceClassification.from_pretrained(model_name)
Örnek metin
text = “I love this movie! It was amazing and very entertaining.”
Metni tokenleştirme ve tensöre çevirme
inputs = tokenizer(text, return_tensors=”pt”)
Modeli çalıştırma
with torch.no_grad(): outputs = model(**inputs)
Çıktıları işle
logits = outputs.logits predicted_class = torch.argmax(logits, dim=1).item()
print(f”Metin sınıfı: {predicted_class + 1} yıldız”)
```markdown
📌 Açıklamalar
- BertForSequenceClassification → Sınıflandırma yapmak için özel BERT modeli
- torch.no_grad() → Modelin eğitilmesini engeller, sadece tahmin yapar. (Bellek kullanımını azaltır.)
- Model, tokenleri işleyerek duygu analizi tahmini yapar.
🧾 Çıktı Yorumu
outputs.logits→ Modelin 1 ila 5 yıldız arasında olasılık değerleri içeren çıktısıdır.torch.argmax(logits, dim=1)→ En yüksek olasılığı olan sınıfı bulur..item()→ Tensörü Python değişkenine çevirir- Örnek çıktı: Metin sınıfı: 5 yıldız
🧠 Örnek: Self Attention ile Metin Özetleme (Kurulum)
```python import numpy as np import nltk from nltk.tokenize import sent_tokenize from sklearn.metrics.pairwise import cosine_similarity import networkx as nx
nltk.download(“punkt”)
```markdown
📌 Açıklamalar
- cosine_similarity: Cümleler arasındaki benzerlikleri hesaplamak için kullanılır.
- networkx: Graf teorisi kütüphanesidir. PageRank algoritması ile cümlelerin önem sırasını belirlemek için kullanılır.
🧪 Örnek: Self Attention ile Metin Özetleme (Fonksiyon)
```python def attention_based_summarizer(text, num_sentences=2): # Cümleleri bölme sentences = sent_tokenize(text)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Kelime vektörlerini temsil etmek için basit bir matris oluşturuyoruz
sentence_vectors = np.array([np.random.rand(100) for _ in sentences])
# Dikkat Skorları (Self-Attention Mantığında)
similarity_matrix = cosine_similarity(sentence_vectors)
# Skorları graf yapısına dökerek PageRank ile en önemli cümleleri belirleyelim
nx_graph = nx.from_numpy_array(similarity_matrix)
scores = nx.pagerank(nx_graph)
# En yüksek skorlu cümleleri seç
ranked_sentences = sorted(((scores[i], s) for i, s in enumerate(sentences)), reverse=True)
# Özet cümlelerini seç
summary = ". ".join([ranked_sentences[i][1] for i in range(min(num_sentences, len(ranked_sentences)))])
return summary
📌 Örnek: Self Attention ile Metin Özetleme (Açıklamalar)
cosine_similarity:
Cümleler arasındaki benzerlikleri ölçer.
Her bir cümle vektörünün diğerlerine ne kadar yakın olduğunu hesaplayarak, cümleler arasındaki ilişkiyi temsil eden bir benzerlik matrisi oluşturur.nx.from_numpy_array:
Bu fonksiyon, oluşturulan benzerlik matrisini bir graf (graph) yapısına dönüştürür.
Grafın düğümleri (nodes) cümleleri, kenarları (edges) ise cümleler arasındaki benzerlik derecelerini temsil eder.nx.pagerank:
Graf üzerindeki düğümlerin (cümlelerin) önem derecelerini hesaplamak için PageRank algoritmasını uygular.
Bu sayede, daha yüksek puana sahip cümleler metnin ana fikrini daha güçlü şekilde yansıtır.
Örnek: Self Attention ile Metin Özetleme
• En yüksek skora sahip cümleleri seçiyoruz.
• min(num_sentences, len(ranked_sentences)) ifadesi, kullanıcı tarafından belirtilen cümle sayısından fazla cümle seçilmesini engeller.
Özet:
Sağlık, eğitim ve finans gibi sektörlerde büyük ilerlemeler kaydedilmektedir.
Gelecekte yapay zekanın daha da yaygınlaşması beklenmektedir.
Özet:
Gelecekte yapay zekanın daha da yaygınlaşması beklenmektedir. Sağlık, eğitim ve finans gibi sektörlerde büyük ilerlemeler kaydedilmektedir.
Örnek: Self Attention ile Metin Özetleme
NOT: Kodu her çalıştırdığınızda özet değişir. Bunun nedeni, metni temsil etmek için rastgele oluşturduğumuz cümle vektörleri kullanmamızdır. Bu vektörler her seferinde rastgele değerler alıyor, bu da benzerlik hesaplamalarını ve dolayısıyla özetin farklı olmasına neden oluyor.
Bunu düzeltmek için, cümle vektörlerinin sabit olmasını sağlamak gerek.
Örnek: Self Attention ile Metin Özetleme
- Özellik Temelli Vektörler Kullanmak: Cümlelerin vektörlerini rastgele değil, kelime gömme (word embeddings) veya önceden eğitilmiş bir model kullanarak temsil edebilirsiniz. Örneğin, Word2Vec, GloVe veya BERT gibi modellerle cümleleri daha anlamlı bir şekilde temsil edebilirsiniz.
- Rastgele Vektörler Yerine Sabit Bir Model Kullanmak: Bunun yerine, spaCy, transformers veya Gensim gibi kütüphaneleri kullanarak cümleleri daha doğru ve sabit vektörlerle temsil edebilirsiniz. Bu sayede, her çalıştırmada aynı vektörler kullanılır ve özet her seferinde aynı olur.
Transformer Modellerinin Avantajları
• Eşzamanlı Hesaplama: Transformer, paralel işlem yapabilme kapasitesine sahip olduğu için, tüm cümleyi veya metni aynı anda işler. RNN ve LSTM’lerde her kelime, bir öncekine bağlı olarak işlenirken, Transformer her kelimeyi aynı anda değerlendirir.
• Eğitim Süresi: Paralel işlem sayesinde, Transformer daha kısa sürede eğitim alır. Bu, özellikle büyük veri setleriyle çalışırken, modelin çok daha hızlı bir şekilde eğitilmesini sağlar. Büyük veri setleri ve uzun metinlerle çalışmak için gereken zaman, geleneksel sıralı modellere kıyasla çok daha azdır.
• Verimli Hesaplama: Paralel işlem yapabilme, donanım kullanımını daha verimli hale getirir. Özellikle GPU veya TPU gibi paralel işlem yapabilen donanımlar üzerinde çalışırken, Transformer’lar çok daha hızlı ve verimli çalışır.
Transformer Modellerinin Avantajları
• Hızlı Eğitilebilirlik: Geleneksel RNN ve LSTM’lerde her bir adımda önceki adımın bilgisinin taşınması gerektiği için işlem sırası önemlidir. Bu, her bir adımın hesaplanmasını ve öğrenilmesini daha yavaş hale getirir. Transformer, her kelimeyi ve kelimeler arasındaki ilişkileri aynı anda işleyerek çok daha hızlı eğitim süresi sağlar.
• Daha Az Hesaplama Kaynağı: Transformer modeli, RNN veya LSTM’lere göre daha az hesaplama kaynağı kullanır. Bu, özellikle büyük veri setlerinde ve büyük modellerde çok önemli bir avantajdır. RNN ve LSTM, uzun dizilerde geri yayılım hesaplamalarında daha fazla bellek ve işlem gücü tüketirken, Transformer daha optimize bir şekilde çalışır.
• Verimli Bellek Kullanımı: Transformer’ın dikkat mekanizması, tüm kelimeler arasındaki ilişkileri aynı anda değerlendirerek, belleği daha verimli kullanır. Bu, özellikle uzun metinlerde modelin daha verimli çalışmasını sağlar.
Transformer Modellerinin Avantajları
• Kapsamlı Bağlantılar: Transformer, dikkat mekanizması sayesinde, her kelimenin diğer tüm kelimelerle olan ilişkisini aynı anda öğrenebilir. Bu, özellikle uzun metinlerde uzun bağımlılıkların öğrenilmesini kolaylaştırır. RNN ve LSTM modelleri, uzun mesafelerdeki ilişkileri öğrenmekte zorlanabilirken, Transformer bu ilişkileri daha hızlı ve doğru bir şekilde öğrenir.
• Etkili Bilgi Aktarımı: Her kelimeyi tüm cümle boyunca dikkate alarak işlem yaptığı için, Transformer, her kelimenin bağlamını tam olarak anlamada daha etkilidir. Bu da modelin daha doğru ve anlamlı sonuçlar üretmesini sağlar.
Transformer Modellerinin Avantajları
• Daha Büyük Modeller: Transformer, paralel işlem yeteneği sayesinde çok daha büyük modeller oluşturulmasına olanak tanır. Model büyüdükçe, daha fazla veri üzerinde çalışabilir ve daha iyi genel performans elde edilebilir. RNN ve LSTM’ler, ardışık yapıları nedeniyle büyüdüklerinde daha fazla zorlukla karşılaşır.
• Ölçeklenebilirlik: Transformer’ın yapısı, geniş veri setlerine ve daha büyük modellere kolayca ölçeklenebilir. Bu, daha büyük dil modelleri (örneğin GPT-3, BERT) için temel yapı taşı olmuştur.
Transformer Modellerinin Avantajları
• Genelleme Kapasitesi: Transformer’lar, paralel işlem ve dikkat mekanizması sayesinde verileri daha etkili bir şekilde işleyebilir ve genelleme yetenekleri daha güçlüdür. Bu, modelin yeni verilere veya daha önce görülmemiş görevlere karşı daha dayanıklı olmasını sağlar.
• Daha Kapsamlı Temsil Öğrenme: Tüm kelimeler arasındaki ilişkileri dikkate alarak daha iyi daha kapsamlı temsil öğrenebilir. Bu da, Transformer’ı daha esnek hale getirir ve çok çeşitli dil işleme görevlerinde başarılı olmasını sağlar.
Transformer Modellerinin Avantajları
• Modüler Yapı: Transformer’ın encoder-decoder yapısı, her iki bileşeni bağımsız olarak geliştirmeye ve kullanmaya olanak tanır. Encoder kısmı, dilin anlamını öğrenirken, decoder kısmı ise uygun çıktıyı üretir. Bu modüler yapı, özel görevler için özelleştirilmiş çözümler sunar.
• Multi-Head Attention: Bu özellik, birden fazla dikkat mekanizmasını paralel olarak çalıştırarak modelin daha fazla bilgi edinmesine olanak tanır. Bu da modelin daha doğru ve kapsamlı sonuçlar üretmesine katkı sağlar.
Transformer Modellerinin Avantajları
• Birçok Görevde Uygulama: Transformer modelleri, çeviri, özetleme, soru-cevap, metin oluşturma gibi çok farklı görevlerde başarıyla kullanılabilir. Bu esneklik, Transformer’ı çok yönlü bir araç haline getirir ve birçok farklı NLP görevinde standart haline gelmesini sağlar.
• Yüksek Performans: Transformer, büyük veri setlerinde bile yüksek performans gösterir. Bu, onun geniş çaplı uygulamalar için ideal bir seçenek olmasını sağlar.
Transformer Modellerinin Zorlukları ve Çözümleri
| Zorluk | Açıklama | Çözüm Önerisi |
|---|---|---|
| Hesaplama Maliyeti | Transformer’lar, özellikle büyük modellerde çok fazla hesaplama gerektirir. | Daha verimli modeller geliştirmek için kuantizasyon, karmaşık olmayan mimariler (örneğin, DistilBERT) veya ince ayarlı küçük modeller kullanılabilir. |
| Büyük Veri Setleri Gereksinimi | Transformer’ların iyi performans göstermesi için çok büyük veri kümelerine ihtiyaç vardır. | Transfer öğrenme kullanarak önceden eğitilmiş modellerden faydalanabilir veya veri artırma (data augmentation) teknikleriyle daha az veriyle iyi sonuçlar elde edilebilir. |
Transformer Modellerinin Zorlukları ve Çözümleri
| Zorluk | Açıklama | Çözüm Önerisi |
|---|---|---|
| Bellek Kullanımı | Özellikle uzun dizileri işlerken self-attention mekanizması nedeniyle bellek tüketimi çok yüksektir. | Linformer, Longformer, Performer gibi verimli attention mekanizmaları kullanılarak bellek tüketimi azaltılabilir. |
| Uzun Metinlerde Performans Zorlukları | Transformer’lar, uzun bağlamları anlamakta zorlanır çünkü self-attention karmaşıklığı O(n²)’dir. | Reformer, Sparse Transformer, Longformer gibi modeller daha uzun bağlamları işlemeye yönelik optimize edilmiş attention mekanizmaları içerir. |
| Gerçek Zamanlı Kullanım Güçlüğü | Büyük Transformer modelleri çalıştırma süresi (inference time) açısından yavaştır. | Pruning, distillation ve model sıkıştırma gibi tekniklerle hız artırılabilir. Edge cihazlara uygun küçük Transformer modelleri (TinyBERT, …) kullanılabilir. |
Transformer Modellerinin NLP ve Yapay Zekâya Etkileri
- Transformer tabanlı modeller (BERT, GPT, T5 vb.), doğal dil işleme (NLP) alanında devrim yaratmıştır.
- Makine çevirisi, metin özetleme, soru yanıtlama, metin üretimi ve duygu analizi gibi birçok görevde insan seviyesinde veya daha iyi performans gösterir.
- Önceden eğitilmiş modeller sayesinde transfer öğrenme mümkün hale gelmiş ve daha az veriyle güçlü modeller eğitilebilir olmuştur.
Gelecekteki Gelişmeler
- Vision Transformers (ViTs): Transformer’lar sadece metinle sınırlı kalmayıp bilgisayarla görme (computer vision) alanında da yaygınlaşmıştır. ResNet ve CNN gibi geleneksel modellerin yerine geçerek görüntü işleme görevlerinde kullanılmaktadır.
- Multimodal Modeller (DALL·E, CLIP, GPT-4 gibi): Tek bir modelin hem metin hem görüntü gibi farklı veri türlerini işlemesi hedeflenmektedir. ChatGPT, Gemini ve Claude gibi modeller, metin tabanlı sorgulara yanıt verirken aynı zamanda görüntü, ses veya video gibi farklı formatları da yorumlayabilir hale gelmiştir.
Gelecekteki Gelişmeler
- Genel Yapay Zekâ (AGI) Yolunda Transformer’ların Rolü: Daha güçlü, daha az veriyle öğrenebilen, daha verimli modeller oluşturuluyor. Hafızaya sahip Transformer modelleri (RetNet, Memorizing Transformers) geliştirilmeye başlanmış durumda.
Transformer’ın Diğer Alanlara Uygulanabilirliği
- Biyoinformatik & Sağlık: Protein yapılarını tahmin etmek için AlphaFold gibi modellerde kullanılıyor.
- Finans & Ekonomi: Piyasa tahminleri, dolandırıcılık tespiti gibi alanlarda Transformer bazlı modeller kullanılıyor.
- Oyun Geliştirme & Simülasyon: Oyun dünyalarında daha gerçekçi NPC’ler (yapay zeka karakterleri) oluşturmak için kullanılıyor.